DIY Metrics: Normalizing by Posession
As promised, today we’re going to talk about normalizing by possession instead of time on court.
First, a but of motivation. Different teams play at different paces. Some teams try to score a lot in transition, some teams try to slow the ball down and make sure they get good shots in the half-court. Part of this is related to a team’s defense and how quickly they get rebounds in the hands of players who can push the ball. While folks make fun of Russell Westbrook for “stealing” rebounds, it’s part of a deliberate strategy by the Thunder to push the ball up court quickly. All this adds up to possessions being arguably a more useful tool by which to compare team and player performance. Scoring 105 points on 110 possessions is a lot different from scoring 105 points on 95 possessions, even if both took the same 48 minutes of game time.
The problem is that it’s a lot harder to do. First, you have to agree on what a “possession” is (not as obvious as it seems), and then you’ve got to actually go into the data and break the game up by those specific tags. Oh, and players can conceivably enter and leave the game within a possession. So there’s that.
Luckily, rather than trying to reinvent the wheel, (Wait a minute, isn’t this whole series an attempt to reinvent the wheel?) we can borrow some stuff. First, definitions:
What is a ‘posession’?
According to our original data source, NBAStuffer, a possession concludes whenever a player/team:
- attempts a field goal,
- misses a shot and does not get the offensive rebound,
- turns the ball over (some sources add “turnovers that are assigned to teams” for a more precise possession calculation),
- goes to the line for two or three shots and either makes the last shot or does not get the rebound of a missed last shot.
This is a little different from the NBA’s official definition:
Section XVIII-Team Possession
A team is in possession when a player is holding, dribbling or passing the ball. Team possession ends when the defensive team gains possession or there is a field goal attempt.
BasketballReference has weird, convoluted formulas because they’re trying to use aggregated stats rather than play-by-play numbers to calculate possession-based statistics, but I think they’re trying to do basically what’s listed above from NBAStuffer. So we’ll just stick with those four bullets above for our purposes.
Getting a bit more precise
In order to translate our definition of a possession above into something we can practically use with our data, we need to be a bit more precise. Take the first two statements from above:
- attempts a field goal,
- misses a shot and does not get the offensive rebound,
These are kinda the same thing; you can’t “mist a shot and not get the offensive rebound” unless you… attempt a field goal. Here’s my translation of conditions where a “possession” ends:
- Made field goal
- Missed field goal without offensive rebound
- Turnover
- Two- or three-shot trips to the line with a make on the last shot OR a miss with no offensive rebound on the last shot.
For our data set, two of these are easy, and the other two are challenging.
Adjusting our cleaning step
To code this information into our data, we adjust our data cleaning step a bit, specifically by adding in a new function:
possession_change <- function(tb){
# This function identifies whether a particular event resulted in a change-of-possession
tb %>%
mutate(possessionchange = map2_lgl(event_type, isoreb,
function(a, b) {a == "turnover" |
a == "shot" |
!b}))
}possession_change makes use of an existing column (event_type) that already tell us if there was a turnover (event_type == "turnover") or a made shot (event_type == "shot", and don’t ask my why it’s coded as “shot” instead of “made shot” or something clearer like that). So that’s numbers 1 and 3 on our list above. And the other two are related. They’re both basically “missed shots that don’t result in an offensive rebound”. possession_change accounts for this using the column, isoreb, which I mean to be read as “is oreb” rather than “iso reb”. To generate this column, I also added the following function:
id_orebs <- function(teamtbl, thatteam){
# this is currently written to interface with team-specific dataframes.
# There's no good reason for this, and it would be more efficient to
# re-write and create this column for the full data table.
ftmiss <- teamtbl %>%
filter(event_type == "free throw", type %in% c("Free Throw 1 of 1",
"Free Throw 2 of 2",
"Free Throw 3 of 3")) %>%
mutate(miss = map_chr(description, str_match, "MISS"),
shooterhome = (player %in% c(o1, o2, o3, o4, o5)), hometeam == thatteam) %>%
filter(miss == "MISS")
omiss <- teamtbl %>% filter(event_type == "miss") %>%
mutate(miss = "MISS",
shooterhome = (player %in% c(o1, o2, o3, o4, o5)), hometeam == thatteam)
...
teamtbl %>% left_join(
(bind_rows(ab, bb) %>% select(isoreb, old_id) %>%
rename(mplay_id = old_id))
)
}The ellipsis in that function is doing a lot of work. There’s another 100 lines of code in there that I’ve omitted. It’s probably the ugliest function I’ve written thus far on this project, and if I wasn’t trying to get this post done on a (self-imposed) deadline, I’d probably re-factor it into a couple (or 10) smaller functions that are more intelligible. I’ll include the full version at the end, but the gist of it is: For missed last free throws from unmade baskets and missed field goals, this function creates a column of logicals that tell you whether the miss resulted in an offensive rebound.
The tricky bit is that the missed free throw or missed shot was coded on a single row of the data frame, and the rebound was on a subsequent line. Usually (but not always) this was the exact next line. Regardless, I had to recover this information and feed it back into the previous line. Doing this involved getting a consistent ID for each event (mplay_id) and then pairing up missed shots with the subsequent rebound information. old_id helped me do that while keeping track of the location of the original roles. Check out the end of the post if you really want to get into the details. (Or see a from-the-wild example of bad code that could be improved!)
The chief result is the two extra lines in get_team_events, which you might recall from previous editions of this series is the principal work-horse function for cleaning the data:
get_team_events <- function(whichteam, tb){
out <- NULL
for(i in seq_along(whichteam$team)){
thatteam <- whichteam$team[i]
teamtbl <- tb %>%
mutate(currentteam = thatteam) %>%
filter(hometeam == currentteam | awayteam == currentteam) %>%
fiveplayers() %>%
mutate(fiveplayers = pmap(list(p1, p2, p3, p4, p5), make_player_list),
p1 = map_chr(fiveplayers, get_player, 1),
p2 = map_chr(fiveplayers, get_player, 2),
p3 = map_chr(fiveplayers, get_player, 3),
p4 = map_chr(fiveplayers, get_player, 4),
p5 = map_chr(fiveplayers, get_player, 5)) %>% select(-fiveplayers) %>%
arrange(game_id) %>%
add_index() %>%
id_orebs(thatteam)
thisteamsplayers <- get_this_teams_players(teamtbl, thatteam)
out <- teamtbl %>%
add_subsections(thisteamsplayers) %>%
possession_change() %>%
pos_count() %>%
mutate(netpoints = pmap_dbl(list(points, currentteam, team), get_net_points)) %>%
select(-team) %>% rename(team = currentteam) %>%
bind_rows(out)
}
out %>% group_by(team) %>% nest(.key = `team events`)
}Plots, but using net ratings!
Now that we’ve got our net ratings, lets plot them! We can basically re-use our code from two weeks ago to make cool visuals using net rating instead of time-normalized plus/minus:
bm <- tmp %>%
unnest() %>%
group_by(team, p1, p2, p3, p4, p5) %>%
summarise(pts = sum(netpoints, na.rm = T),
npos = length(unique(possessioncount)),
netrtg = pts / npos * 100)
bm %>%
filter(npos > 200) %>%
ggplot(aes(x = netrtg, y = 1, size = npos, color = team)) +
geom_jitter(width = 0) +scale_color_nba() + theme_bw() + ylab("") +
theme(legend.position = "top") + xlab("Net Rating") +
scale_y_continuous(labels = NULL) +
guides(size = guide_legend(title = "Possessions Played")) +
facet_wrap(~team)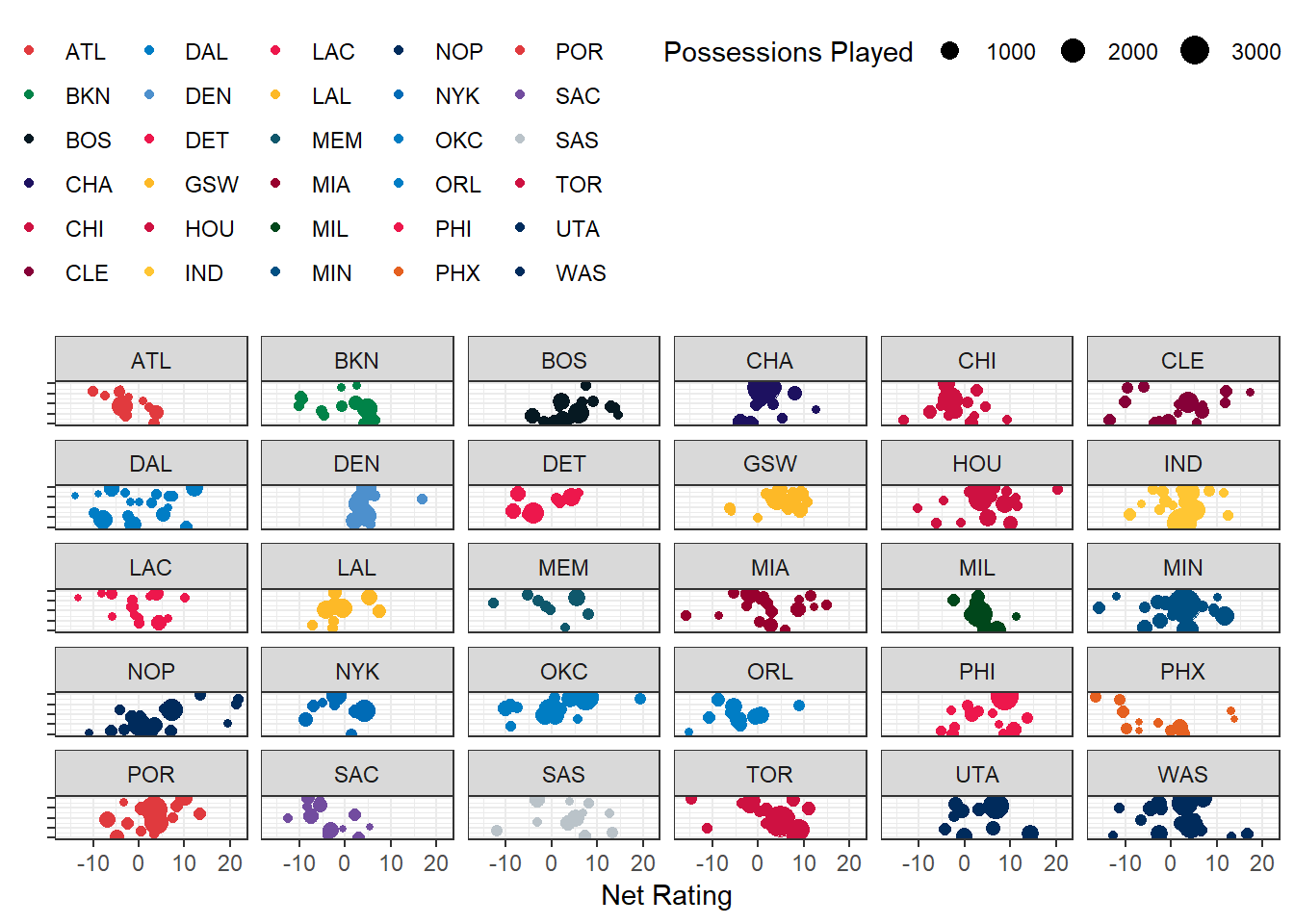
good stuff!
How to ID ORebs
You’ve been warned…
id_orebs <- function(teamtbl, thatteam){
# this is currently written to interface with team-specific dataframes.
# There's no good reason for this, and it would be more efficient to
# re-write and create this column for the full data table.
ftmiss <- teamtbl %>%
filter(event_type == "free throw", type %in% c("Free Throw 1 of 1",
"Free Throw 2 of 2",
"Free Throw 3 of 3")) %>%
mutate(miss = map_chr(description, str_match, "MISS"),
shooterhome = (player %in% c(o1, o2, o3, o4, o5)), hometeam == thatteam) %>%
filter(miss == "MISS")
omiss <- teamtbl %>% filter(event_type == "miss") %>%
mutate(miss = "MISS",
shooterhome = (player %in% c(o1, o2, o3, o4, o5)), hometeam == thatteam)
smiss <- bind_rows(ftmiss, omiss) %>%
select(game_id, mplay_id, miss, shooterhome) %>%
mutate(old_id = mplay_id,
mplay_id = mplay_id + 1) %>%
arrange(mplay_id)
#two weird issues remain: One, sometimes the data frame has a substitute recorded after the 2nd ft instead of before it. we shoudl try to skip these and just get the subsequent play. Two, sometimes the rebound is omitted all together and there's just another play next. This we can basically ignore, assuming that the team that recovered the ball is indicated by the player shooting the next shot.
smiss$mplay_id[left_join(smiss, teamtbl)$event_type == "sub"] <-
smiss$mplay_id[left_join(smiss, teamtbl)$event_type == "sub"] + 1
ab <- smiss %>% left_join(teamtbl) %>%
filter(event_type == "rebound") %>%
select(event_type, description, shooterhome, o1, o2, o3, o4, o5, player,
hometeam, shooterhome, mplay_id, old_id) %>%
separate(description, into = "rbname", sep = " ", extra = "drop") %>%
mutate(homelong = map_chr(hometeam, city_to_team),
rbhome = (player %in% c(o1, o2, o3, o4, o5)), hometeam == thatteam,
teamrbhome = rbname == homelong,
isoreb = pmap_lgl(list(rbhome, teamrbhome, shooterhome),
function(a, b, c) {(a||b) && c }))
bb <- smiss %>% left_join(teamtbl) %>%
filter(event_type != "rebound", !is.na(player)) %>%
select(event_type, description, shooterhome, o1, o2, o3, o4, o5,
player, hometeam, shooterhome, mplay_id, old_id) %>%
separate(description, into = "rbname", sep = " ", extra = "drop") %>%
mutate(homelong = map_chr(hometeam, city_to_team),
rbhome = (player %in% c(o1, o2, o3, o4, o5)), hometeam == thatteam,
teamrbhome = rbname == homelong,
isoreb = pmap_lgl(list(rbhome, teamrbhome, shooterhome),
function(a, b, c) {(a||b) && c }))
teamtbl %>% left_join(
(bind_rows(ab, bb) %>% select(isoreb, old_id) %>%
rename(mplay_id = old_id))
)
}